# 正则学习
# 什么是正则
正则其实就是一种描述文本内容组成规律的表示方式。
测试地址:https://regex101.com/
# 正则基本概念
# 元字符
元字符就是指那些在正则表达式中具有特殊意义的专用字符,元字符是构成正则表达式的基本元件。
常见的元字符有下面几种
- 特殊单字符
.匹配任意字符(换行除外)\d匹配任意数字,\D匹配任意非数字\w匹配任意字母数字下划线,\W匹配任意非字母数字下划线\s匹配任意空白符,\S匹配任意非空白符
- 空白符
\r回车符\n换行符\f换页符\t制表符(就是tab键)\v垂直制表符- 空格,直接匹配空格就行
- 范围
|表示或[...]多选一[x-y]匹配 x 到 y 之间的任意元素(按ASCIL表,包含 x 和 y)[^...]取反,不能是括号中的任意单个元素
- 量词(和重复次数有关的)
*0 到多次+1 到多次?0 到 1 次{m}出现 m 次{m, }至少出现 m 次{m, n}出现 m 到 n 次
- 断言
\b单词边界$结束,^开始
# 贪婪模式和非贪婪模式
在正则中,表示次数的量词默认是贪婪的,在贪婪模式下,会尝试尽可能最大长度去匹配。
这就是贪婪模式
let str = "aaabb"; | |
let rex = /a+/g; | |
str.match(rex); // ['aaa'] |
我们可以在量词后面加上英文的问号 ( ? ),这时这个量词就变成了非贪婪的,非贪婪模式会尽可能短地去匹配,也就是找出长度最小且满足要求的
let str = "aaabb"; | |
let rex = /a+?/g; | |
str.match(rex); // ['a', 'a', 'a'] |
# 分组和引用
括号在正则中的功能就是用于分组
由多个元字符组成某个部分,应该被看成一个整体的时候,可以用括号括起来表示一个整体,这是括号的一个重要功能
# 分组
可以看下面的例子
不分组的情况(匹配一个 a 后面跟着的多个 b)
let str = "abbabab"; | |
let rex = /ab+/g; | |
str.match(rex); // ['abb', 'ab', 'ab'] |
分组的情况(匹配 ab 这个字符串)
let str = "abbabab"; | |
let rex = /(ab)+/g; | |
str.match(rex); // ['ab', 'abab'] |
# 引用
括号在正则中可以用于分组,被括号括起来的部分 “子表达式” 会被保存成一个子组。
那分组和编号的规则是怎样的呢?其实很简单,用一句话来说就是,第几个括号就是第几个分组。
let str = "2020-11-15 14:12:05"; | |
let rex = /(\d{4}-\d{2}-\d{2}) (\d{2}:\d{2}:\d{2})/; | |
// 第一个是匹配上的结果 第二第三个是对应的子组 | |
str.match(rex); // ['2020-11-15 14:12:05', '2020-11-15', '14:12:05'] |
# 不保存子组
在括号里面的会保存成子组,但有些情况下,你可能只想用括号将某些部分看成一个整体,后续不用再用它,类似这种情况,在实际使用时,是没必要保存子组的。这时我们可以在括号里面使用?: 不保存子组。
如果正则中出现了括号,那么我们就认为,这个子表达式在后续可能会再次被引用,所以不保存子组可以提高正则的性能。除此之外呢,这么做还有一些好处,由于子组变少了,正则性能会更好,在子组计数时也更不容易出错。
let str = "2020-11-15 14:12:05"; | |
let rex = /(?:\d{4}-\d{2}-\d{2}) (?:\d{2}:\d{2}:\d{2})/; | |
// 第一个是匹配上的结果 第二第三个是对应的子组 | |
str.match(rex); // ['2020-11-15 14:12:05'] |
# 括号嵌套
我们只需要数左括号(开括号)是第几个,就可以确定是第几个子组。
比如下面的例子

# 命名分组
分组编号存在一些问题
- 编号得数在第几个位置,不易操作
- 续如果发现正则有问题,改动了括号的个数,还可能导致编号发生变化
所以一些编程语言提供了命名分组(named grouping),这样和数字相比更容易辨识,不容易出错。你可以使用在括号里加上 ?<name> 来为分组命名
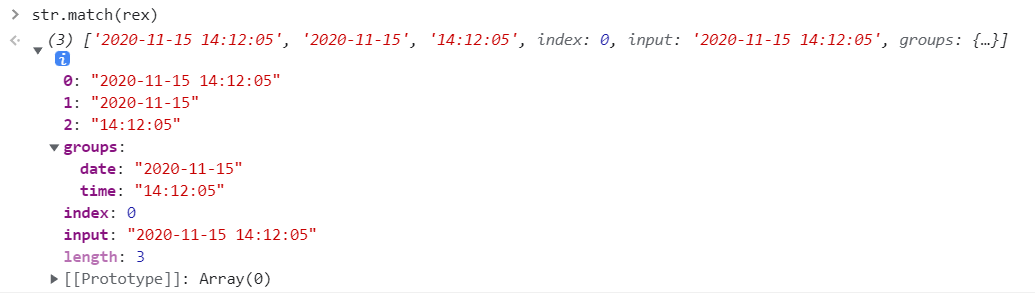
let str = "2020-11-15 14:12:05"; | |
let rex = /(?<date>\d{4}-\d{2}-\d{2}) (?<time>\d{2}:\d{2}:\d{2})/; | |
str.match(rex); |
匹配的结果如下
# 分组引用
如果我们要找重复出现的单词,我们使用分组引用这个操作,表达前面出现的单词再次出现这个含义
比如下面的代码
普通的引用方法是 \...
let str = "cat cat"; | |
let rex = /(\w+) \1/g; | |
str.match(rex); // ['cat cat'] |
也可以使用命名分组,引用规则是 \k<...>
let str = "cat cat"; | |
let rex = /(?<word>\w+) \k<word>/g; | |
str.match(rex); // ['cat cat'] |
# 匹配模式
所谓匹配模式,指的是正则中一些改变元字符匹配行为的方式,常见的匹配模式有四种
- 不区分大小写模式(Case-Insensitive)
- 点号通配模式(Dot All)
- 多行匹配模式(Multiline)
- 注释模式(Comment)
在其他语言里,模式修饰符是通过 (? 模式标识) 的方式来表示的。
我们只需要把模式修饰符放在对应的正则前,就可以使用指定的模式了。
# 不区分大小写模式
当我们把模式修饰符放在整个正则前面时,就表示整个正则表达式都是不区分大小写的。
在 JavaScript 里,使用 /regex/i 表示正则是不区分大小写的
let str = "Cat"; | |
let rex = /cat/gi; | |
str.match(rex); // ['Cat'] |
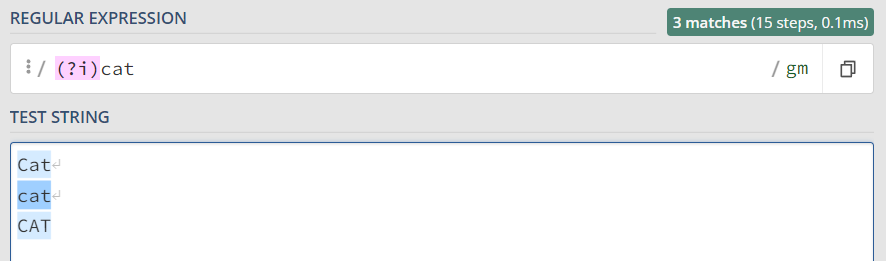
其他语言里,使用 (?i) 表示整条正则都不区分大小写
let rex = /(?i)cat/g; |
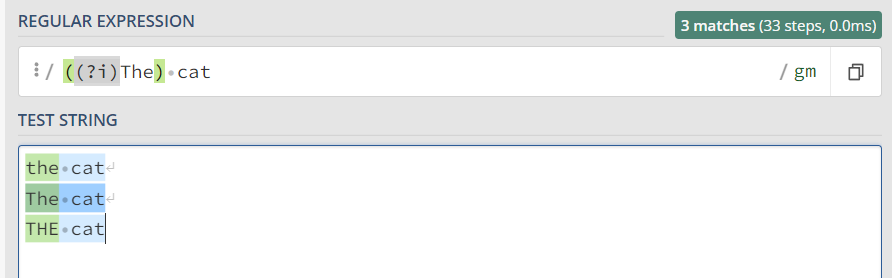
我们可以使用括号来更精确地表示匹配模式应用的范围,用括号把修饰符和正则部分括起来,可以让不区分大小写只作用于这个括号里的内容。
let rex = /((?i)The) cat/g; |
# 点号通配模式
最初的定义里, . 可以匹配除了换行以外的任意字符,当我们需要匹配真正的 “任意” 符号的时候,可以使用 [\s\S] 或 [\d\D] 或 [\w\W] 等。
或者,使用点号通配模式来指定 . 的匹配行为。在点号通配模式中,让 . 可以匹配上包括换行的任何字符。
其他语言中,使用 (?s) 来使用该模式
JavaScript 中,使用 /regex/s 来使用该模式
let str = ` | |
dog | |
cat | |
`; | |
let rex = /.+/sg; | |
str.match(rex); // ['\n\tdog \n\tcat\n'] |
# 多行匹配模式
多行模式的作用在于,使 ^ 和 $ 能匹配上每行的开头或结尾。
换而言之,使用了多行模式后,
^和$的行为从匹配全文的开头结尾,变成匹配每行的开头结尾
JavaScript 中,我们可以使用 /regex/m 来指定这个模式
其他语言中,我们可以使用模式修饰符号 ?m 来指定这个模式。
let str = `Log: execute func1 | |
Log: execute func2`; | |
let rex = /^(?:Log\:\s)(?:.+)/g; | |
str.match(rex); // ['Log: execute func1'] | |
let rex = /^(?:Log\:\s)(?:.+)/gm; | |
str.match(rex); // ['Log: execute func1', 'Log: execute func2'] |
# 断言
在有些情况下,我们对要匹配的文本的位置也有一定的要求。
为了解决这个问题,正则中提供了一些结构,只用于匹配位置,而不是文本内容本身,这种结构就是断言。
常见的有三种
- 单词边界
- 行的开始 / 结束
- 环视
# 单词边界(Word Boundary)
单词的组成一般可以用元字符 \w+ 来表示, \w 包括了大小写字母、下划线和数字(即 [A-Za-z0-9_] )。
那如果我们能找出单词的边界,也就是当出现了 \w 表示的范围以外的字符,比如引号、空格、标点、换行等这些符号
我们就可以在正则中使用 \b 来表示单词的边界。 \b 中的 b 可以理解为是边界(Boundary)这个单词的首字母。

let str = `tom asked me if I would go fishing with him tomorrow.`; | |
let rex = /\btom\b/gm; | |
str.match(rex); // ['tom'] |
let str = `tom asked me if I would go fishing with him tomorrow.`; | |
let rex = /tom/gm; | |
str.match(rex); // ['tom', 'tom'] 会同时匹配出 tomorrow 里的 tom |
# 行的开始或者结束
和单词的边界类似,在正则中还有文本每行的开始和结束,使用 ^ 和 $ 来进行位置界定
行的结尾使用换行符进行匹配。当然,回车(
\r)和换行(\n)其实是两个概念,并且在不同的平台上,换行的表示也是不一样的。Windows、Linux、macOS 平台上换行的表示方式如下。

示例如下
// 使用 ^ 匹配开头 | |
let str = `Log: execute func1 | |
Log: execute func2`; | |
let rex = /^(?:Log\:\s)(?:.+)/gm; | |
str.match(rex); // ['Log: execute func1', 'Log: execute func2'] |
// 使用 $ 匹配结束 | |
let str = `vue.js | |
react.js | |
reset.css`; | |
let rex = /.+\.js$/gm; | |
str.match(rex); // ['vue.js', 'react.js'] |
# 环视
环视是要求匹配部分的前面或后面要满足(或不满足)某种规则
举个例子。邮政编码的规则是由 6 位数字组成。现在要求你写出一个正则,提取文本中的邮政编码。根据规则,我们很容易就可以写出邮编的组成 \d{6} 。我们可以使用下面的文本进行测试
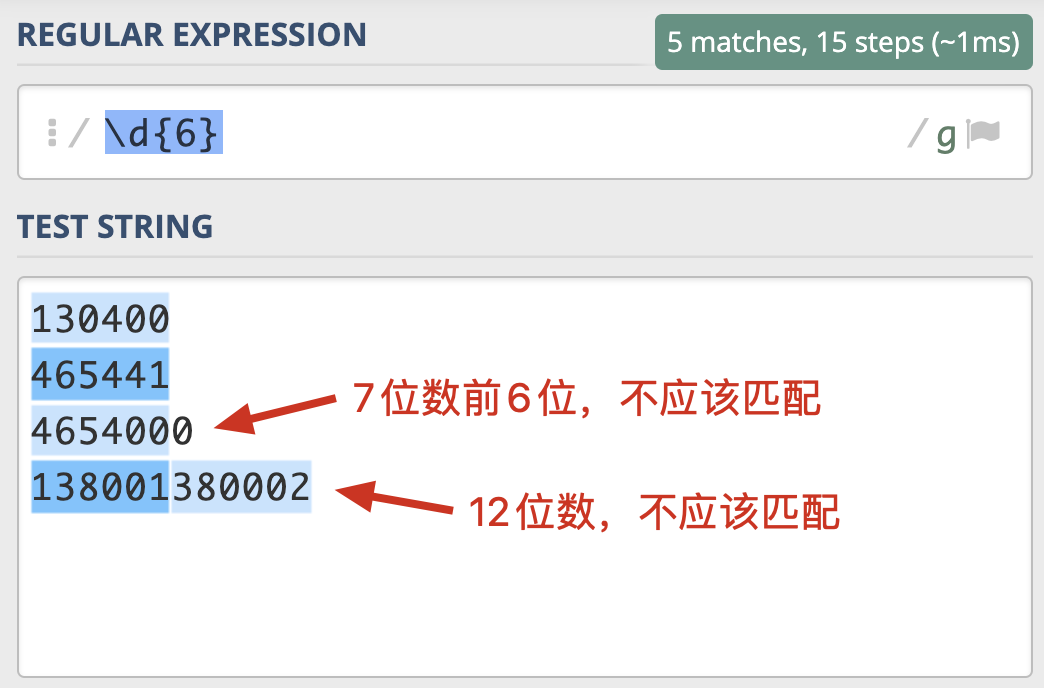
这显然是不符合要求的,因此,我们可以使用环视来解决这个问题

所以,正则可以优化为 /(?<!\d)\d{6}(?!\d)/gm ,这样就符合期望了

# 其他
String.prototype.match():https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/String/match