# 序
前端安全应该是老生常谈的话题了,毕竟世界上没有绝对安全的系统,我们工程师能做的只是让入侵变得更难,这篇文章会介绍前端工程师需要注意的两种攻击,XSS 和 CSRF 攻击。
# XSS
XSS 是 Cross-site scripting 的缩写,即跨站脚本攻击,在 XSS 攻击中,攻击者把恶意代码注入到网站中,普通用户在打开网站时,被注入的恶意代码便会执行。需要注意的是,攻击者并不能直接攻击受害者的的电脑,而是利用受害者访问的网站上的漏洞,通过注入等方式让恶意 JS 代码在受害者的电脑上运行。
如果你的网站被 XSS 攻击成功了,那么攻击者可能会做什么事呢?
- 窃取用户敏感信息,如 cookie,身份令牌等被盗取
- 记录键盘信息,通过在密码框上绑定 input 事件来监听用户输入,然后把密码发送到攻击者的服务器
- 生成虚假表单,诱导用户输入敏感信息
# XSS 攻击的分类
# 持久型 XSS (Persistent XSS)
存储型 XSS 应该是最常见的 XSS 攻击了,存储型 xss 一出现在网站留言板,评论处,个人资料处,等需要用户可以对网站写入数据的地方。比如一个论坛评论处由于对用户输入过滤不严格,导致攻击者在写入一段窃取 cookie 的恶意 JavaScript 代码到评论处,这段恶意代码会写入数据库,当其他用户浏览这个写入代码的页面时,网站从数据库中读取恶意代码显示到网页中被浏览器执行,导致用户 cookie 被窃取,攻击者无需受害者密码即可登录账户。
举个例子
这是一个输入页面
<textarea id="input" cols="30" rows="10"></textarea> | |
<button id="btn">Submit</button> | |
<script> | |
const input = document.getElementById('input'); | |
const btn = document.getElementById('btn'); | |
let val; | |
input.addEventListener('change', (e) => { | |
val = e.target.value; | |
}, false); | |
btn.addEventListener('click', (e) => { | |
fetch('http://localhost:5000/save', { | |
method: 'POST', | |
body: val | |
}); | |
}, false); | |
</script> |
服务器保存输入,然后在其他用户访问时把输入嵌入到页面中返回
const http = require('http'); | |
let userInput = ''; | |
function handleRequest(req, res) { | |
const method = req.method; | |
res.setHeader('Access-Control-Allow-Origin', '*'); | |
res.setHeader('Access-Control-Allow-Headers', 'Content-Type') | |
if (method === 'POST' && req.url === '/save') { | |
let body = ''; | |
req.on('data', chunk => { | |
body += chunk; | |
}); | |
req.on('end', () => { | |
if (body) { | |
userInput = body; | |
} | |
res.end(); | |
}); | |
} else { | |
res.writeHead(200, {'Content-Type': 'text/html; charset=UTF-8'}); | |
res.write( | |
`<html><body><div id="app">${userInput}</div></body></html>` | |
); | |
res.end(); | |
} | |
} | |
const server = new http.Server(); | |
server.listen(5000); | |
server.on('request', handleRequest); |
我们提交一段 JS 脚本

当再访问 http://localhost:5000 时,会出现下面的弹框

这时,只要任意一个用户访问网站,恶意代码就会在用户的浏览器中执行。
# 反射型 XSS (Reflected XSS)
反射型 XSS 通常是使用 URL 的形式来攻击的,过程如下
- 攻击者制作一个包含恶意代码的 URL
- 普通用户点击了攻击者制作的 URL
- 该服务器在响应中包含来自 URL 的恶意代码,而且没有转义
- 恶意代码在普通用户的浏览器中执行
攻击者的网站
<div>这是攻击者的网站</div> | |
<a href="http://localhost:5000/?s=<script>alert('你被攻击啦, 下次不要乱点链接了哦')<script/>">劲爆大片点这里</a> |
这是正常网站的服务器
const express = require("express"); | |
const app = express(); | |
const port = 5000; | |
app.get("*", (req, res) => { | |
res.write(`<html><body><div>you search key word : ${req.query.s}</div></body></html>`); | |
res.end(); | |
}) | |
app.listen(port, () => { | |
console.log(`server listen on ${port}`); | |
}); |
开启服务器访问 http://localhost:5000/?s=abc 的效果是这样的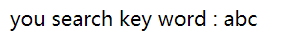
但是如果点了攻击者的诱导链接,恶意 JS 就会执行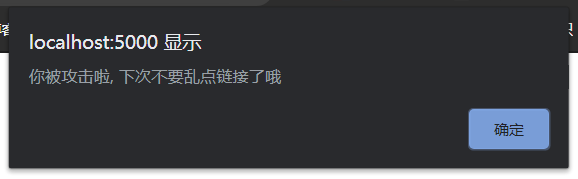
# 基于 DOM 的 XSS (DOM-based XSS)
基于 DOM 的 XSS 和上面两种很类似,只是这次背锅的不是不加验证的服务器而是不加验证的合法 JS 了,攻击的过程如下。
- 攻击者制作一个包含恶意代码的 URL
- 普通用户点击了攻击者制作的 URL
- 服务器收到请求,但响应中不包含恶意字符串。
- 普通用户的浏览器执行合法脚本,将恶意脚本插入页面。
- 恶意代码在普通用户的浏览器中执行
举个例子
index.html
<body> | |
<div id="app">你搜索的关键字是 : </div> | |
<script> | |
const app = document.querySelector("#app"); | |
let query = parseQueryString(location.search); | |
app.innerHTML = `你搜索的关键字是 : ${query.s}` | |
function parseQueryString(url) { | |
let obj = {}; | |
let keyValue = []; | |
let key = "", value = ""; | |
let paraString = url.substring(url.indexOf("?") + 1, url.length).split("&"); | |
for (let i in paraString) { | |
keyValue = paraString[i].split("="); | |
key = keyValue[0]; | |
value = keyValue[1]; | |
obj[key] = value; | |
} | |
return obj; | |
} | |
</script> | |
</body> |
服务器
const express = require("express");
const http = require("http");
const app = express();
const port = 5000;
const path = require("path");
const staticRoot = path.resolve(__dirname, "public");
app.use(express.static(staticRoot, {
index : 'index.html'
}));
app.listen(port, () => {
console.log(`server listen on ${port}`);
});
恶意链接
<div>这是攻击者的网站</div> | |
<a href="http://localhost:5000/?s=<script>alert(`你被攻击啦, 下次不要乱点链接了哦`)</script>">劲爆大片点这里</a> |
恶意 JS 同样会执行
# 防御 XSS
# 设置 cookie 的 HttpOnly
HttpOnly 最早是由微软提出,并在 IE 6 中实现的,至今已经逐渐成为一个标准,各大浏览器都支持此标准。具体含义就是,如果某个 Cookie 带有 HttpOnly 属性,那么这一条 Cookie 将被禁止读取,也就是说,JavaScript 读取不到此条 Cookie,不过在与服务端交互的时候,Http Request 中仍然会带上这个 Cookie。
服务器在设置网站 cookie 时设置 cookie 的 HttpOnly,我们使用 cookie-parse 这个库可以很方便的设置 cookie
res.cookie("token", val, {
httpOnly : true
});
设置 HttpOnly 不能完全阻止 XSS,它只是防止了用户的用户凭证被盗取,我们还需要其他的方式
# 不要轻易使用 innerHTML
如果不是万不得已,不要使用 innerHTML ,因为 innerHTML 会把里面的内容当成 DOM 来解析,如果用户的输入中有 script 标签,那么 script 标签里的代码也会执行,所以尽可能使用 innerText 进行开发。
# 在输入输出时进行编码
如果你万不得已需要用到 innerHTML , 那你一定要对用户的输入进行编码,编码可以让用户的输入在解析时按字符串来解析
简单的编码规则:
| 特殊字符 | 实体编码 |
|---|---|
| & | & ; |
| < | < ; |
| > | > ; |
| " | " ; |
| ' | ' ; |
| / | / ; |
另外还有更详细的编码规则,可以直接使用
const HtmlEncode = (str) => { | |
// 设置 16 进制编码,方便拼接 | |
const hex = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f']; | |
// 赋值需要转换的 HTML | |
const preescape = str; | |
let escaped = ""; | |
for (let i = 0; i < preescape.length; i++) { | |
// 获取每个位置上的字符 | |
let p = preescape.charAt(i); | |
// 重新编码组装 | |
escaped = escaped + escapeCharx(p); | |
} | |
return escaped; | |
// HTMLEncode 主要函数 | |
//original 为每次循环出来的字符 | |
function escapeCharx(original) { | |
// 默认查到这个字符编码 | |
let found = true; | |
//charCodeAt 获取 16 进制字符编码 | |
const thechar = original.charCodeAt(0); | |
switch (thechar) { | |
case 10: return "<br/>"; break; // 新的一行 | |
case 32: return " "; break; // space | |
case 34: return """; break; // " | |
case 38: return "&"; break; // & | |
case 39: return "'"; break; // ' | |
case 47: return "/"; break; // / | |
case 60: return "<"; break; // < | |
case 62: return ">"; break; // > | |
case 198: return "Æ"; break; // Æ | |
case 193: return "Á"; break; // Á | |
case 194: return "Â"; break; // Â | |
case 192: return "À"; break; // À | |
case 197: return "Å"; break; // Å | |
case 195: return "Ã"; break; // Ã | |
case 196: return "Ä"; break; // Ä | |
case 199: return "Ç"; break; // Ç | |
case 208: return "Ð"; break; // Ð | |
case 201: return "É"; break; // É | |
case 202: return "Ê"; break; | |
case 200: return "È"; break; | |
case 203: return "Ë"; break; | |
case 205: return "Í"; break; | |
case 206: return "Î"; break; | |
case 204: return "Ì"; break; | |
case 207: return "Ï"; break; | |
case 209: return "Ñ"; break; | |
case 211: return "Ó"; break; | |
case 212: return "Ô"; break; | |
case 210: return "Ò"; break; | |
case 216: return "Ø"; break; | |
case 213: return "Õ"; break; | |
case 214: return "Ö"; break; | |
case 222: return "Þ"; break; | |
case 218: return "Ú"; break; | |
case 219: return "Û"; break; | |
case 217: return "Ù"; break; | |
case 220: return "Ü"; break; | |
case 221: return "Ý"; break; | |
case 225: return "á"; break; | |
case 226: return "â"; break; | |
case 230: return "æ"; break; | |
case 224: return "à"; break; | |
case 229: return "å"; break; | |
case 227: return "ã"; break; | |
case 228: return "ä"; break; | |
case 231: return "ç"; break; | |
case 233: return "é"; break; | |
case 234: return "ê"; break; | |
case 232: return "è"; break; | |
case 240: return "ð"; break; | |
case 235: return "ë"; break; | |
case 237: return "í"; break; | |
case 238: return "î"; break; | |
case 236: return "ì"; break; | |
case 239: return "ï"; break; | |
case 241: return "ñ"; break; | |
case 243: return "ó"; break; | |
case 244: return "ô"; break; | |
case 242: return "ò"; break; | |
case 248: return "ø"; break; | |
case 245: return "õ"; break; | |
case 246: return "ö"; break; | |
case 223: return "ß"; break; | |
case 254: return "þ"; break; | |
case 250: return "ú"; break; | |
case 251: return "û"; break; | |
case 249: return "ù"; break; | |
case 252: return "ü"; break; | |
case 253: return "ý"; break; | |
case 255: return "ÿ"; break; | |
case 162: return "¢"; break; | |
case '\r': break; | |
default: found = false; break; | |
} | |
if (!found) { | |
// 如果和上面内容不匹配且字符编码大于 127 的话,用 unicode (非常严格模式) | |
if (thechar > 127) { | |
let c = thechar; | |
let a4 = c % 16; | |
c = Math.floor(c / 16); | |
let a3 = c % 16; | |
c = Math.floor(c / 16); | |
let a2 = c % 16; | |
c = Math.floor(c / 16); | |
let a1 = c % 16; | |
return "&#x" + hex[a1] + hex[a2] + hex[a3] + hex[a4] + ";"; | |
} else { | |
return original; | |
} | |
} | |
} | |
} |
# 在输入输出时验证输入
你可能会觉得有些疑惑,既然上一步已经对 HTML 做了编码,那为什么还要进行验证呢,因为有些使用,你不能单纯的把用户的输入当成字符串,比如说你做了一个富文本编辑器,用户可以使用 HTML 来编写内容,但是要对一些危险的操作进行处理,比如用户写了以下代码
<img src="0" alt="" onerror="alert(1)"/> |
这个代码如果原封不动展示到网页上,就会触发 XSS 攻击,我们要做的就是对这个输入进行处理。这里我们使用一个已经比较成熟的库 js-xss 来处理
let xss = require("xss");
var options = {
whiteList: {
a: ["href", "title", "target"],
img : ["src", "alt"]
}
};
let html = xss('<img src="0" alt="" onerror="alert(1)"/>', options);
使用 whiteList (白名单) 配置可以让用户输入的 html 中尽可能的只有安全字段,从而达到过滤恶意代码的效果。
# CSP(Content Security Policy)
内容安全策略 (CSP) 是一个额外的安全层,用于检测并削弱某些特定类型的攻击,包括跨站脚本 (XSS) 和数据注入攻击等。无论是数据盗取、网站内容污染还是散发恶意软件,这些攻击都是主要的手段。
这个比较复杂,我就不具体讲解了,需要的朋友可以看看下面几个教程
Content Security Policy 入门教程
Content Security Policy (CSP) 介绍
# CSRF
# CSRF 是什么
CSRF 是 Cross Site Request Forgery 的简称,中文名是跨站请求伪造,这种攻击是通过冒用已登录用户的身份,模拟正常用户的操作来完成的

它的原理如下:
- 用户访问正常站点,登录后,获取到了正常站点的令牌,以 cookie 的形式保存

- 用户访问恶意站点,恶意站点通过某种形式去请求了正常站点(请求伪造),迫使正常用户把令牌传递到正常站点,完成攻击

# 常见的 CSRF 攻击方式
# form 表单
攻击者的网站
<body> | |
<form method="post" id="form" action="http://localhost:5000/article"> | |
<input value="CSRF攻击" name="content"/> | |
</form> | |
</body> | |
<script> | |
let form = document.querySelector("#form"); | |
form.submit(); | |
history.back(); | |
</script> |
服务器
const express = require("express");
const app = express();
const port = 5000;
const path = require("path");
const staticRoot = path.resolve(__dirname, "public");
const cookieParser = require("cookie-parser");
app.use(cookieParser());
app.use(express.static(staticRoot));
app.post("/article", (req, res) => {
console.log(req.cookies);
res.write(JSON.stringify({
name : 'sena'
}));
res.end();
});
app.listen(port, () => {
console.log(`server listen on ${port}`);
});
正常的网站
<label> | |
<textarea id="article"></textarea> | |
</label> | |
<button id="button">提交</button> | |
<script> | |
let article = document.querySelector("#article"); | |
let button = document.querySelector("#button"); | |
let url = "http://localhost:5000/article"; | |
button.onclick = function () { | |
const data = article.value; | |
console.log(data); | |
fetch(url, { | |
method: 'POST', | |
body : data | |
}).then(res => res.json()).then((res) => { | |
console.log(res); | |
}) | |
} | |
</script> |
如果在正常的网站里,用户保存了身份信息在 cookie 里,然后再访问攻击者的网站,cookie 就随着请求一起携带到服务器,form 表单一般会用于 post 攻击

# a 标签
如果目标网站允许 get 请求,可通过超链接攻击,点击时也会携带 cookie 到请求中
<a href="http://localhost:8080/article/save?content=CSRF">劲爆大片</a> |
# 图片加载
img 标签的 src 属性同理,也会携带 cookie 到请求中
<img src="http://localhost:8080/article/save?content=CSRF" /> |
# 防御 CSRF
# 设置 cookie 的 SameSite
现在很多浏览器都支持禁止跨域附带的 cookie,只需要把 cookie 设置的 SameSite 设置为 Strict 即可
SameSite 有以下取值:
- Strict:严格,所有跨站请求都不附带 cookie,有时会导致用户体验不好
- Lax:宽松,所有跨站的超链接、GET 请求的表单、预加载连接时会发送 cookie,其他情况不发送
- None:无限制
这种方法非常简单,极其有效,但前提条件是:用户不能使用太旧的浏览器
# 验证 referer 和 Origin
页面中的二次请求都会附带 referer 或 Origin 请求头,向服务器表示该请求来自于哪个源或页面,服务器可以通过这个头进行验证,如果不是可以信任的网站就不处理这个请求
但某些浏览器的 referer 是可以被用户禁止的,尽管这种情况极少
# 使用非 cookie 令牌
这种做法是要求身份验证的 token 放在请求头中或者其他地方,在每次请求时用 JS 添加
# 二次验证
对敏感操作进行二次验证,比如各种各样的验证码,缺点是正常用户使用时会觉得比较繁琐
# 表单随机数
这种做法是服务端渲染时,生成一个一次性的随机数,客户端提交时要提交这个随机数,然后服务器端进行对比